


Choosing between Opus vs Sonnet vs Haiku is not just a performance preference — it is a cost, speed, and architecture decision with real business consequences. Pick the wrong model and you will either overspend significantly or deliver outputs that miss the quality bar your product needs.
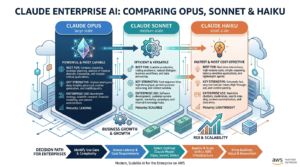
Anthropic’s Claude model family is intentionally tiered. Each model is designed for a distinct operating context, and the performance gap between tiers is meaningful. Claude Opus is the most capable reasoning model Anthropic offers. Claude Sonnet sits in the high-capability middle tier, serving as the workhorse for most production applications. Claude Haiku prioritizes speed and economy over depth.
This guide gives you a clear, technically grounded comparison across every dimension that matters: reasoning depth, speed, pricing, context window behavior, and real-world use cases. No vague generalities just the information you need to make an informed architecture decision.
The Claude Model Family: Understanding the Architecture
Anthropic built the Claude model family around a tiered intelligence architecture. Rather than offering a single general-purpose model, Anthropic gives developers and organizations the ability to match model capability to task complexity — a design philosophy that is increasingly standard across leading AI providers.
The three tiers in the Claude family are:
- Tier 1 — Claude Opus: Maximum intelligence, highest cost, designed for tasks where reasoning quality is the primary constraint
- Tier 2 — Claude Sonnet: High intelligence, optimized for production deployment, balancing capability and cost at scale
- Tier 3 — Claude Haiku: Ultra-fast, minimum cost, designed for high-volume workloads where task complexity is low
All three models share Anthropic’s core safety design, Constitutional AI training approach, and large context windows. They differ primarily in the depth of reasoning they apply to complex problems, the speed at which they generate responses, and the cost per token.
Current model versions available via the Anthropic API and Amazon Bedrock include claude-opus-4-6, claude-sonnet-4-6, and claude-haiku-4-5. Anthropic updates each tier independently, meaning a new Sonnet release does not necessarily coincide with a new Opus release.
Claude Opus: Maximum Reasoning for Hard Problems
Claude Opus is Anthropic’s flagship model for tasks that require genuine multi-step reasoning, synthesis of large and complex information sets, and nuanced judgment. It is built for the use cases where getting the answer right matters more than getting it fast.
Where Opus Outperforms the Other Models
The clearest differentiator for Opus is performance on tasks with high logical complexity. These include:
- Legal document analysis: Interpreting contract clauses, identifying conflicting terms, and synthesizing implications across long, dense documents
- Financial modeling and analysis: Reasoning through multi-variable financial scenarios, audit findings, and regulatory filings
- Advanced software engineering: Complex architecture review, debugging distributed systems, and generating well-reasoned code for non-trivial problems
- Research synthesis: Drawing coherent conclusions from multiple lengthy papers or reports with conflicting findings
- Strategic business analysis: Evaluating trade-offs, modeling scenarios, and generating nuanced recommendations from ambiguous inputs
- Advanced RAG (Retrieval Augmented Generation): Tasks where many retrieved documents must be compared, cross-referenced, and reasoned over simultaneously
Opus and Context Window Utilization
One often-overlooked advantage of Opus is how effectively it uses large context windows. When given a 100,000-token context window full of complex material, Opus consistently retrieves and reasons over relevant information more accurately than Sonnet. For long-document tasks where precision matters, this context utilization difference is significant.
Sonnet and Haiku also support large context windows, but the quality of reasoning across the full context — particularly on tasks requiring cross-document comparison tends to degrade more quickly with shorter prompts and less relevant information.
The Honest Trade-off: Opus Is Expensive and Slow
Claude Opus comes with two clear costs: higher latency and higher per-token pricing. For interactive, real-time user-facing applications, Opus latency can be noticeable. For batch processing or asynchronous analysis tasks, this matters less.
On cost: Opus is typically several times more expensive per token than Sonnet, which is significantly more expensive than Haiku. The exact multiplier varies with model version updates — always verify current pricing at anthropic.com/pricing. Running Opus at production scale on high-frequency queries can generate substantial API costs quickly.
| Pro Tip The most cost-effective use of Opus is in human-in-the-loop workflows — where an engineer or analyst reviews the output before it goes anywhere. In these contexts, the higher cost per call is offset by the reduction in human correction time on complex tasks. Opus earns its price when the alternative is an hour of expert review. |
Claude Sonnet: The Production Standard for Enterprise AI
Claude Sonnet is where the vast majority of production AI workloads belong. It delivers intelligence that is close to Opus for most real-world tasks, at a speed and cost profile that is sustainable at scale. If you are building an enterprise AI assistant, a RAG-based knowledge platform, or a developer tool, Sonnet is almost certainly your correct starting point.
Why Sonnet Dominates Production Deployments
The key insight about Sonnet is that the quality gap between Sonnet and Opus is far smaller than the cost gap. For tasks like document summarization, structured data extraction, customer service automation, code explanation, and knowledge Q&A — Sonnet’s output is functionally equivalent to Opus for the vast majority of inputs.
This matters because in production, you are paying for every request, not just the hard ones. Running Opus on 10,000 daily requests that Sonnet handles equally well means paying a significant premium for no user-visible benefit.
- Enterprise knowledge assistants and internal search: Sonnet handles multi-turn Q&A over enterprise documents effectively at low latency
- RAG production systems: Sonnet synthesizes retrieved chunks accurately across most document types and query categories
- Customer service automation: Multi-turn conversation, intent resolution, and structured response generation across thousands of daily interactions
- AI copilots for employees: HR, legal, finance, and IT assistance where Sonnet’s reasoning depth is sufficient for 90% of real queries
- Code generation and review: Sonnet generates production-quality code, explains existing code, and catches most classes of bugs effectively
- Content generation pipelines: Blog posts, summaries, reports, and marketing content at production volume
Sonnet’s Position in Multi-Model Architectures
In architectures that use multiple Claude models, Sonnet is almost always the primary response-generation model. It handles the bulk of the workload while Haiku manages routing and classification upstream, and Opus handles escalated complex queries.
This positioning reflects Sonnet’s design: high enough intelligence to handle most production tasks, fast enough for real-time use, and cheap enough to deploy at scale without destroying your API budget.
Claude Haiku: Speed, Scale, and Economy

Claude Haiku is not a downgrade from Sonnet — it is a different tool for a different job. Haiku is purpose-built for workloads where response time is measured in milliseconds, request volume is high, and the reasoning required per request is bounded and predictable.
Haiku’s Core Use Cases
- Intent detection and message classification: Determining what a user is asking before routing to a more capable model
- Content moderation: Classifying content at high throughput with low latency requirements
- Structured data extraction from short inputs: Pulling entities, dates, categories, and metadata from short text
- Simple FAQ and chatbot responses: Handling predefined response patterns where answer quality is determined by the knowledge base, not model reasoning
- Real-time suggestions and autocomplete: Latency-sensitive features where sub-200ms response time is essential
- Batch pre-processing: Preparing, filtering, or reformatting large volumes of text before passing to a more capable model
Haiku as the Gateway in Multi-Model Systems
Haiku’s most strategic application in enterprise AI is as the first-layer processor in a tiered architecture. It can receive every incoming request, perform lightweight classification or entity extraction, and make a routing decision — sending the request to Sonnet for standard handling or flagging it for Opus when complexity indicators are detected.
This gateway role dramatically reduces the average cost per request across a high-volume system. If Haiku correctly routes 70% of requests to itself for direct resolution, with 25% going to Sonnet and 5% to Opus, the blended cost per request is a fraction of running everything through Sonnet or Opus.
| Pro Tip Build your routing logic around task complexity signals, not just keyword matching. Factors like query length, the presence of conditional reasoning, requests for comparison or analysis, and multi-document references are reliable indicators that a request should escalate from Haiku to Sonnet or Opus. |
Opus vs Sonnet vs Haiku: Complete 2026 Comparison Table
The table below summarizes key differences across the dimensions that matter most for production deployment decisions.
| Dimension | Claude Opus | Claude Sonnet | Claude Haiku |
| Reasoning Quality | Highest — best for complex, multi-step logic | High — handles most enterprise tasks well | Moderate — best for simple, bounded tasks |
| Response Speed | Slowest — latency notable for real-time use | Fast — suitable for real-time applications | Fastest — sub-second for most requests |
| Cost Per Token | Highest — significant at scale | Mid-range — sustainable at production volume | Lowest — optimized for high-volume economics |
| Context Window Use | Best — deep reasoning across full context | Strong — effective for typical enterprise docs | Limited — degrades on very large contexts |
| Best Standalone Use | Complex analysis, research, advanced code | Enterprise AI, RAG, copilots, content pipelines | Classification, routing, moderation, chatbots |
| Role in Multi-Model Arch. | Top-tier escalation — rare calls, hard problems | Primary production model — most requests | First-layer router — high volume, low complexity |
| Real-Time User Facing | Possible but latency may be noticeable | Yes — recommended for interactive products | Yes — ideal for speed-critical features |
| Amazon Bedrock Access | Available | Available | Available |
| Ideal Team Profile | ML engineers, researchers, legal/finance AI | Enterprise teams, product builders, developers | DevOps, automation teams, high-volume ops |
Real-World Use Cases by Role and Architecture
For CTOs and Enterprise Architects
The architecture decision is not ‘which model’ it is ‘how do we design routing so the right model handles each request category.’ A tiered system using all three models consistently outperforms single-model deployments on both cost and quality metrics.
A practical enterprise architecture on Amazon Bedrock:
- User request arrives and is routed through a Lambda function
- Haiku performs intent classification and complexity scoring in under 200ms
- Simple queries (FAQs, structured lookups) are answered by Haiku directly
- Standard queries are passed to Sonnet with relevant RAG context from Amazon OpenSearch
- High-complexity queries (legal, financial, technical deep-dives) are escalated to Opus
This architecture reduces blended cost per request by 50-75% compared to routing everything to Sonnet, and by 80-90% compared to using Opus for all requests.
For Developers and ML Engineers
The practical test for model selection is simple: run your most representative 50 inputs through all three models and evaluate output quality. Do not use benchmark results as a proxy for your specific domain.
- Start prototyping with Sonnet — it is fast to iterate and covers most use cases
- Test Opus only on inputs where Sonnet’s output consistently fails your quality bar
- Use Haiku for any preprocessing, classification, or routing tasks in your pipeline
- In agentic systems, use Sonnet as the reasoning agent and Haiku for tool-call routing and sub-task delegation
- Pin model versions in production — behavior can shift between claude-sonnet-4-5 and claude-sonnet-4-6
For Startup Founders
Budget efficiency at the early stage means not over-engineering your model selection. The right default for most startups is Sonnet. It covers product use cases from MVP through Series A scale without requiring architectural redesign.
- MVP chatbots and AI assistants: Sonnet
- Content generation and summarization tools: Sonnet
- High-scale consumer features at seed stage: Haiku with Sonnet for complex queries
- AI-powered analytics or research tools: Evaluate Opus for the core reasoning task, Sonnet for supporting tasks
How to Benchmark Opus vs Sonnet vs Haiku for Your Specific Workload
General benchmarks tell you how models perform on standardized tests. Your production use case is not a standardized test. The only reliable way to select the right model is to evaluate all three against your actual data and quality criteria.
A Practical Benchmarking Framework
- Define your quality rubric first: What does a good output look like for your use case? Define this before running any model — not after. Use criteria like accuracy, completeness, format adherence, reasoning quality, or domain-specific correctness.
- Build a representative test set: Collect 50-100 real inputs from your use case. Include the full range — easy queries, medium queries, and the hard edge cases that break models. Skewing toward easy inputs produces misleading benchmark results.
- Run blind evaluation: Generate outputs from all three models without labeling which model produced each result. Have evaluators score outputs against your quality rubric without knowing which model they are reviewing.
- Measure cost and latency alongside quality: Calculate the cost per satisfactory output for each model, not just cost per request. A cheaper model that requires retries or human correction may be more expensive in practice.
- Test on your production context window size: If your prompts include 50,000 tokens of retrieved context, test with 50,000 tokens — not 2,000 tokens. Context window behavior differs significantly from short-prompt behavior.
Building Multi-Model Pipelines: The Production Architecture Pattern
The most sophisticated production deployments of Claude do not use a single model they build pipelines that leverage each model’s strengths at the right stage of processing.
The Three-Layer Architecture
Layer 1 — Classification and Routing (Haiku): Every request enters the system through Haiku. At this layer, Haiku classifies the request type, extracts key entities, scores complexity, and determines routing. Cost: minimal. Latency: sub-200ms. This layer adds almost no perceptible delay to the user experience.
Layer 2 — Primary Processing (Sonnet): The majority of requests land here. Sonnet handles knowledge retrieval synthesis, content generation, code assistance, and multi-turn conversation. RAG retrieval happens at this layer — relevant documents are fetched from the vector store and provided as context to Sonnet for response generation.
Layer 3 — Complex Reasoning (Opus): A small percentage of requests — typically 5-15% depending on the use case domain — require Opus-level reasoning. These are requests where Sonnet consistently produces lower-quality outputs: multi-document synthesis, advanced code architecture, deep financial or legal analysis. Opus is invoked asynchronously where possible to manage latency impact.
This architecture is deployable on Amazon Bedrock using AWS Lambda for routing logic, Amazon OpenSearch or DynamoDB for the knowledge base, and Amazon S3 for document storage. The model routing logic can be as simple as a complexity classifier or as sophisticated as a learned routing model.
Signals That You Are Using the Wrong Model
Model selection is not a one-time decision. As your application scales, your user base evolves, and new model versions are released, the right model for your workload may change. Watch for these signals.
Signals You Should Upgrade from Sonnet to Opus
- Consistent user feedback that responses miss key nuances or make logical errors on complex queries
- Evaluation scores on your quality rubric consistently falling below threshold on the hard 20% of inputs
- Support escalation rate is high for AI-generated responses on complex topics
- Your use case involves multi-document comparison, legal or financial reasoning, or advanced code architecture
Signals You Should Downgrade from Sonnet to Haiku
- Your API cost is growing faster than your user base — indicating over-provisioned model capability
- The majority of your queries are short, structured, or follow predictable patterns
- Response latency is a higher priority than response depth
- Your outputs are primarily structural (classification labels, entity extraction, yes/no decisions) rather than generative
Signals You Need a Multi-Model Architecture
- Your application handles a wide range of query complexity — some trivially simple, some genuinely hard
- Your cost per request is too high with Sonnet but quality degrades unacceptably with Haiku
- Different user segments have fundamentally different task requirements (e.g., basic users vs. power users in an enterprise tool)
Conclusion: The Right Model for the Right Job
The Opus vs Sonnet vs Haiku decision comes down to one principle: match model capability to task complexity. Using a more powerful model than the task requires is waste. Using a less powerful model than the task demands is a product failure.
Key takeaways:
- Claude Opus is for genuinely hard problems — complex reasoning, long-document analysis, advanced engineering — where accuracy matters more than speed or cost
- Claude Sonnet is the right default for most production deployments — enterprise knowledge tools, RAG systems, copilots, and developer tooling
- Claude Haiku is not a compromise — it is the correct tool for classification, routing, moderation, and high-volume lightweight tasks where Sonnet-level reasoning is unnecessary
- Multi-model architectures combining all three consistently outperform single-model deployments on both quality and cost metrics
- Benchmark on your actual use case, not general benchmarks — the performance distribution across your specific inputs determines the right model, not aggregate scores
Whether you are deploying via the Anthropic API directly or through Amazon Bedrock, the three-tier model architecture gives you the tools to build AI systems that are both intelligent and economically sustainable. Start with Sonnet, instrument your outputs, and let real usage data drive your model evolution.
