


Choosing Your Cloud Data Warehouse Platform
The Snowflake vs AWS vs Azure decision represents one of the most strategic technology choices for data-driven organizations in 2026, with the global cloud data warehouse market projected to exceed $15 billion. As enterprises accelerate digital transformation and analytics initiatives, selecting the right cloud data platform impacts everything from query performance and scalability to total cost of ownership and vendor flexibility.
Snowflake vs AWS vs Azure isn’t simply a technical comparison—it’s a fundamental business decision affecting data strategy. Snowflake emerged as the purpose-built cloud data warehouse disrupting traditional approaches, while AWS Redshift pioneered cloud analytics as part of Amazon’s comprehensive cloud ecosystem, and Azure Synapse Analytics leverages Microsoft’s enterprise relationships with deep integration across the Microsoft data and AI stack.
For CTOs, data architects, startup founders, and ML engineers evaluating Snowflake vs AWS Redshift vs Azure Synapse, the decision extends beyond feature matrices to encompass existing cloud investments, multi-cloud strategies, data governance requirements, and analytics workload characteristics. Organizations already standardized on AWS or Azure face different considerations than those pursuing cloud-agnostic data platforms or building modern data stacks from scratch.
What is Snowflake?
Snowflake is a purpose-built cloud data platform designed from the ground up for the cloud, offering a unique architecture that separates compute from storage. Founded in 2012 and launched publicly in 2014, Snowflake revolutionized data warehousing by eliminating infrastructure management complexity while delivering near-unlimited scalability, instant elasticity, and seamless data sharing capabilities across multiple cloud providers.

Key Features of Snowflake
Multi-Cloud Architecture and Data Cloud
Snowflake’s defining advantage is its cloud-agnostic platform available across AWS, Azure, and Google Cloud Platform:
- Cross-cloud data sharing: Share live data across organizations without copying or moving data, even across different cloud providers
- Single unified platform: Consistent experience regardless of underlying cloud infrastructure (AWS, Azure, GCP)
- Data marketplace: Access third-party data sets and share data products through Snowflake Data Marketplace
- Secure data collaboration: Share data with external partners while maintaining governance and security controls
- Multi-cloud/multi-region deployment: Deploy across clouds and regions without vendor lock-in
This architecture enables true data mobility and eliminates traditional data silos between cloud platforms.
Separation of Compute and Storage
Snowflake’s unique architecture provides unprecedented flexibility:
- Independent scaling: Scale compute resources (virtual warehouses) independently from storage without downtime
- Unlimited concurrency: Multiple virtual warehouses can query the same data simultaneously without performance degradation
- Automatic scaling: Virtual warehouses automatically scale up/down based on workload demands (multi-cluster warehouses)
- Zero-copy cloning: Create instant, zero-storage clones of entire databases for testing and development
- Time travel and fail-safe: Query historical data up to 90 days and recover from accidental data deletion
Near-Zero Administration
Snowflake eliminates traditional database administration overhead:
- Fully managed service: No infrastructure provisioning, patching, tuning, or maintenance required
- Automatic query optimization: Built-in query optimizer without manual index creation or partition tuning
- Automatic clustering: Data is automatically organized for optimal query performance
- Transparent updates: New features and performance improvements deployed automatically without downtime
- Built-in data protection: Continuous data protection with automatic backups and encryption
Performance and Optimization
Snowflake delivers consistent query performance at scale:
- Columnar storage: Compressed columnar format optimized for analytical queries
- Micro-partition architecture: Data automatically divided into optimized micro-partitions
- Result caching: Automatic caching of query results for instant response times
- Materialized views: Pre-computed aggregations for faster complex query performance
- Search optimization service: Accelerate point lookup queries by up to 100×
Use Cases for Snowflake
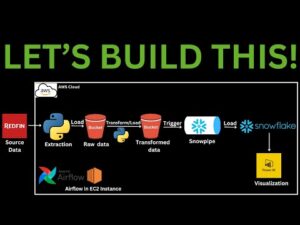
Modern Data Warehouse:
- Consolidating data from multiple sources for enterprise analytics
- Replacing legacy on-premises data warehouses (Teradata, Oracle, Netezza)
- Supporting thousands of concurrent users with predictable performance
- Enabling self-service analytics for business users
Data Lake and Data Engineering:
- Querying semi-structured data (JSON, Avro, Parquet, ORC) without transformation
- Building modern data platforms with ELT pipelines
- Processing streaming data with Snowpipe for continuous ingestion
- Supporting data science workloads with Python, Spark, and ML integrations
Data Sharing and Collaboration:
- Sharing live data with customers, partners, and suppliers
- Monetizing data through Snowflake Data Marketplace
- Breaking down data silos across business units
- Enabling secure multi-party analytics and clean rooms
Application Development:
- Building data-intensive applications with Snowflake as backend
- Powering customer-facing analytics dashboards
- Supporting SaaS applications with multi-tenant data architecture
- Enabling real-time data applications with Snowpark
What are AWS Data Services?
Amazon Web Services provides a comprehensive suite of data and analytics services with AWS Redshift as its flagship cloud data warehouse. Part of the world’s leading cloud platform with 32% market share, AWS data services offer deep integration across the broader AWS ecosystem, enabling organizations to build complete data platforms using services like S3 data lakes, Glue ETL, Athena serverless queries, and extensive machine learning capabilities through SageMaker.

Key Features of AWS Redshift
Massively Parallel Processing (MPP) Architecture
AWS Redshift delivers high-performance analytics through distributed computing:
- Columnar storage: Compressed columnar data format reducing I/O and improving query speed
- Parallel processing: Distributes data and queries across multiple nodes for fast performance
- Node types: RA3 nodes with managed storage, DC2 dense compute, DS2 dense storage options
- Concurrency scaling: Automatically adds transient capacity for burst query workloads
- Result caching: Frequently accessed query results cached for sub-second response times
Deep AWS Ecosystem Integration
Redshift’s competitive advantage lies in seamless AWS service integration:
- S3 data lake integration: Query S3 data directly with Redshift Spectrum without loading
- AWS Glue integration: Automatic schema discovery and ETL job orchestration
- Lake Formation: Unified data governance across data lakes and warehouses
- SageMaker integration: Build ML models directly on Redshift data with SQL
- QuickSight: Native BI tool integration for visualization and dashboards
- IAM security: Unified identity and access management across AWS services
Cost Optimization Features
AWS provides multiple mechanisms for controlling Redshift costs:
- Reserved Instance pricing: 1-3 year commitments for up to 75% discounts
- RA3 architecture: Pay separately for compute and managed storage with automatic scaling
- Pause and resume: Suspend clusters during non-use periods to eliminate compute charges
- Concurrency scaling pricing: Only pay for additional capacity when needed
- Workload management: Prioritize queries and allocate resources based on business priorities
Advanced Analytics Capabilities
Redshift supports sophisticated analytical workloads:
- Federated queries: Join Redshift data with RDS PostgreSQL, Aurora, and S3 in single query
- Materialized views: Pre-compute complex joins and aggregations for faster queries
- Machine learning integration: Create, train, and deploy ML models using SQL with SageMaker Autopilot
- Spatial analytics: Built-in support for geospatial data and location-based queries
- Streaming ingestion: Real-time data ingestion from Kinesis Data Streams
Use Cases for AWS Redshift
Enterprise Data Warehousing:
- Centralizing analytics for AWS-centric organizations
- Migrating from on-premises Oracle, Teradata, or Netezza
- Building multi-petabyte data warehouses
- Supporting complex ETL workflows with AWS Glue
Big Data Analytics:
- Querying data lakes with Redshift Spectrum and S3
- Processing log analytics at massive scale
- Running ad-hoc queries across structured and unstructured data
- Integrating with EMR for Spark-based transformations
Business Intelligence and Reporting:
- Powering executive dashboards with QuickSight
- Supporting thousands of concurrent BI users
- Providing self-service analytics to business users
- Enabling real-time operational reporting
Machine Learning and AI:
- Training models on large datasets with SageMaker integration
- Implementing predictive analytics with SQL-based ML
- Building recommendation engines with Redshift data
- Supporting data science workloads with Python and Jupyter notebooks
What are Azure Data Services?
Microsoft Azure provides an integrated suite of data and analytics services with Azure Synapse Analytics as its unified analytics platform. Launched in 2019 as the evolution of Azure SQL Data Warehouse, Synapse brings together data warehousing, big data processing, and data integration in a single service. Azure’s data platform leverages Microsoft’s enterprise dominance with deep integration across Power BI, Azure Data Lake Storage, Azure Machine Learning, and Microsoft’s comprehensive enterprise software stack.
Key Features of Azure Synapse Analytics
Unified Analytics Platform
Azure Synapse’s architecture combines multiple analytics capabilities:
- Dedicated SQL pools: Provisioned data warehouse with MPP architecture for enterprise workloads
- Serverless SQL pools: Pay-per-query model for ad-hoc analytics on data lakes
- Apache Spark pools: Built-in Spark for big data processing and machine learning
- Data Explorer: Fast, interactive analytics on streaming and telemetry data
- Pipelines: Code-free ETL/ELT orchestration similar to Azure Data Factory
- Synapse Studio: Unified workspace for data engineering, warehousing, and visualization
Deep Microsoft Ecosystem Integration
Azure Synapse provides unmatched Microsoft technology integration:
- Power BI integration: Native connectivity with DirectQuery for real-time dashboards
- Azure Data Lake Storage Gen2: Tightly integrated data lake with hierarchical namespace
- Azure Machine Learning: Build and deploy ML models directly on Synapse data
- Microsoft 365 integration: Analyze Office, Teams, and SharePoint data
- Azure Purview: Unified data governance and catalog across Azure data estate
- Azure Active Directory: Seamless enterprise identity and access management
Hybrid and Multi-Cloud Capabilities
Azure emphasizes flexibility across deployment models:
- Azure Arc integration: Query data in AWS S3 or Google Cloud Storage from Synapse
- On-premises connectivity: ExpressRoute for secure, high-bandwidth connections
- PolyBase: Query external data in SQL Server, Oracle, MongoDB without moving
- Synapse Link: Real-time analytics on operational data from Cosmos DB and Dataverse
- Hybrid transactional/analytical processing (HTAP): Unified operational and analytical workloads
Enterprise Data Management
Synapse provides comprehensive governance and security:
- Column-level security: Granular access control at column level
- Row-level security: Filter data based on user context
- Dynamic data masking: Automatically obscure sensitive data
- Transparent data encryption: Automatic encryption at rest
- Advanced threat protection: Detect anomalous database activities
- Azure Purview integration: End-to-end data lineage and cataloging
Use Cases for Azure Synapse Analytics
Enterprise Data Warehousing:
- Modernizing SQL Server data warehouses in the cloud
- Consolidating analytics for Azure-centric organizations
- Supporting enterprise reporting with Power BI integration
- Enabling governed self-service analytics across business units
Big Data and Advanced Analytics:
- Processing petabyte-scale data with Spark pools
- Running machine learning workloads with Azure ML integration
- Analyzing IoT telemetry and streaming data
- Supporting data science teams with Python, R, and Scala
Real-Time Analytics:
- Operational analytics with Synapse Link on Cosmos DB
- Streaming data analysis with Data Explorer pools
- Near real-time dashboards with Power BI Direct Query
- Event-driven analytics on Azure Event Hubs data
Hybrid and Multi-Cloud Analytics:
- Querying data across on-premises, AWS, GCP, and Azure
- Building unified analytics on diverse data sources
- Gradual cloud migration with hybrid architecture
- Multi-cloud data platform with Azure Arc
Snowflake vs AWS vs Azure: Key Differences
Understanding the architectural, operational, and strategic differences between Snowflake, AWS Redshift, and Azure Synapse Analytics clarifies where each platform excels.
Architecture and Design Philosophy
Snowflake Architecture:
- Shared-data, multi-cluster: Complete separation of compute and storage with shared data layer
- Cloud-agnostic: Runs on AWS, Azure, and GCP with identical experience
- Zero administration: Fully managed with automatic optimization and maintenance
- Elastic compute: Instantly scale virtual warehouses up/down or add concurrent warehouses
AWS Redshift Architecture:
- Shared-nothing MPP: Data distributed across compute nodes with local storage (DC2/DS2) or managed storage (RA3)
- AWS-native: Deeply integrated into AWS ecosystem but AWS-only
- Manual optimization: Requires distribution keys, sort keys, and vacuum operations
- Elastic with limits: Resize clusters but requires downtime for classic clusters
Azure Synapse Architecture:
- Unified platform: Combines dedicated SQL pools (MPP), serverless SQL, and Spark in single service
- Azure-native: Integrated with Microsoft data and AI stack, Azure-only
- Flexible compute: Choose provisioned (dedicated pools) or serverless (pay-per-query)
- Hybrid capabilities: Query across Azure, on-premises, and multi-cloud sources
Performance and Scalability Comparison
Query Performance:
| Aspect | Snowflake | AWS Redshift | Azure Synapse |
| Architecture | Separation of compute/storage | Tightly coupled (DC2/DS2), managed storage (RA3) | Dedicated pools + serverless options |
| Concurrency | Near-unlimited with multi-cluster | Concurrency scaling for bursts | Workload management required |
| Auto-scaling | Automatic multi-cluster scaling | Manual resize or concurrency scaling | Manual scaling for dedicated pools |
| Caching | Result caching across virtual warehouses | Result caching per cluster | Result set caching |
| Optimization | Automatic micro-partitioning | Manual distribution and sort keys | Manual distribution, statistics |
When to Choose Snowflake
Snowflake represents the optimal choice for organizations prioritizing simplicity, multi-cloud flexibility, and data sharing capabilities.
Ideal Scenarios for Snowflake
- Multi-Cloud or Cloud-Agnostic Strategy
Organizations avoiding vendor lock-in benefit from Snowflake’s architecture:
- Deploy on AWS, Azure, or GCP with identical experience
- Move workloads between clouds without application changes
- Share data across organizations on different cloud providers
- Avoid deep commitment to single cloud vendor
- Minimal Administration and Maintenance
Teams lacking specialized database administrators choose Snowflake:
- Zero infrastructure management or tuning required
- Automatic query optimization without indexes or partitions
- No vacuum, reorg, or maintenance window operations
- Focus on analytics instead of database administration
- Data Sharing and Collaboration
Organizations monetizing data or partnering extensively:
- Share live data with customers, partners, suppliers instantly
- Participate in Snowflake Data Marketplace
- Enable secure multi-party data collaboration
- Build data products and applications on shared data
When to Choose AWS Redshift
AWS Redshift excels for organizations deeply invested in the AWS ecosystem and requiring comprehensive cloud platform integration.
Ideal Scenarios for AWS Redshift
- AWS-Native Organizations
Companies standardized on AWS benefit from Redshift’s integration:
- Seamless integration with S3, Glue, EMR, SageMaker, QuickSight
- Unified IAM security and access management
- Leverage existing AWS skills and certifications
- Consolidated AWS billing and enterprise agreements
- Data Lake and Hybrid Analytics
Organizations with S3 data lakes leverage Redshift’s capabilities:
- Query data lakes with Redshift Spectrum without loading
- Combine warehouse and lake house architectures
- Process data with EMR/Spark then analyze in Redshift
- Build unified analytics on structured and unstructured data
- Predictable, Consistent Workloads
Enterprises with steady analytics usage patterns:
- Reserved Instance pricing provides 40-75% cost savings
- Predictable performance with appropriately sized clusters
- Cost-effective for consistent 24/7 workloads
- Mature workload management for resource prioritization
When to Choose Azure Synapse Analytics
Azure Synapse Analytics represents the optimal choice for Microsoft-centric organizations and those requiring unified analytics platforms.
Ideal Scenarios for Azure Synapse
- Microsoft Ecosystem Organizations
Enterprises standardized on Microsoft technologies:
- Seamless Power BI integration for enterprise dashboarding
- Native Azure Active Directory authentication
- Azure Data Lake Storage Gen2 for data lake foundation
- Microsoft 365 data analytics (Teams, SharePoint, Office)
- Hybrid and Multi-Cloud Analytics
Organizations with complex data landscapes:
- Query on-premises SQL Server and Oracle with PolyBase
- Azure Arc enables queries across AWS S3 and Google Cloud Storage
- Unified management for hybrid and multi-cloud data
- Gradual cloud migration with consistent tooling
- Unified Analytics Platform Requirements
Teams consolidating data warehousing, big data, and ETL:
- Single platform for SQL, Spark, and data integration
- Synapse Studio unified workspace for all analytics workloads
- Reduce tool sprawl with integrated capabilities
- Consistent security, governance, and monitoring
Frequently Asked Questions (FAQ)
Q1: Cost — Which platform is most cost-effective?
A: Snowflake is best for variable workloads with pay-per-use and auto-scaling. Redshift is cheaper for 24/7 workloads using Reserved Instances. Synapse offers middle-ground pricing with serverless pools for ad-hoc queries.
Q2: Can Snowflake, AWS Redshift, and Azure Synapse work together?
A: Yes. Organizations often use multi-platform strategies: Snowflake for multi-cloud analytics, Redshift for AWS-native workloads, Synapse for Microsoft ecosystem. Tradeoff: higher complexity and data transfer costs.
Q3: Which platform has the best query performance?
A: Snowflake excels for variable workloads with auto-scaling and caching. Redshift delivers high throughput for optimized workloads. Synapse performs comparably with dedicated pools when tuned.
Q4: Is Snowflake easier to use than AWS or Azure data services?
A: Yes. Snowflake requires zero administration and automatic query optimization. Synapse is moderately complex, while Redshift needs more DB expertise and manual tuning.
Q5: Which platform has the best data sharing & cloud flexibility?
A: Snowflake leads with live, multi-cloud data sharing. Redshift supports AWS-only sharing (same region). Synapse enables sharing via external tables & Azure Data Share but is less seamless.
Conclusion: Making Your Snowflake vs AWS vs Azure Decision
The Snowflake vs AWS vs Azure decision ultimately depends on your existing cloud investments, workload characteristics, data sharing requirements, and organizational priorities. No platform is universally superior—each excels for specific scenarios and enterprise profiles. GoCloud helps organizations evaluate these platforms to choose the best fit for their business.
