


AWS container orchestration services have become the backbone of modern cloud infrastructure, enabling organizations to deploy, scale, and manage containerized applications with minimal operational overhead. AWS offers four distinct container orchestration solutions—ECS (Elastic Container Service), EKS (Elastic Kubernetes Service), Fargate, and App Runner each optimized for different architectural requirements and operational capabilities.
Understanding when to use each AWS container orchestration service is critical for making informed infrastructure decisions. ECS provides AWS-native orchestration with tighter EC2 integration; EKS delivers managed Kubernetes for multi-cloud portability; Fargate eliminates server management entirely; App Runner handles deployment complexity with minimal configuration. This comprehensive guide explores each service, compares architectural approaches, and provides production-grade frameworks for implementing AWS container orchestration at scale.
1. AWS Container Orchestration Landscape: Portfolio Architecture and Service Selection
The Four AWS Container Orchestration Services
AWS provides four primary container orchestration services, each solving different problems:
- ECS (Elastic Container Service): AWS-native container orchestration using Tasks and Services. Tightly integrated with EC2, supporting full customization and control. Optimal for organizations standardizing on AWS infrastructure.
- EKS (Elastic Kubernetes Service): Managed Kubernetes service offering CNCF-certified Kubernetes clusters. Provides multi-cloud portability and leverages extensive Kubernetes ecosystem. Optimal for organizations prioritizing cloud-agnostic architecture.
- Fargate: Serverless container compute platform abstracting infrastructure management. Supports both ECS and EKS, enabling focus on applications rather than infrastructure. Optimal for cost-sensitive and operations-light deployments.
- App Runner: Fully managed container deployment service handling build, deployment, and scaling automatically. Minimal configuration required. Optimal for rapid prototyping and small-to-medium applications.
Service Selection Framework
Selecting the appropriate service requires evaluating: infrastructure control requirements, operational complexity tolerance, multi-cloud portability needs, cost sensitivity, and team expertise. Organizations with AWS-only infrastructure and full infrastructure control requirements typically choose ECS. Multi-cloud organizations or those prioritizing Kubernetes leverage EKS. Cost-optimized and operations-minimal teams select Fargate or App Runner.
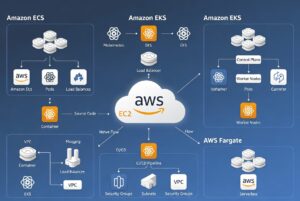
2. ECS Deep Dive: AWS-Native Container Orchestration at Scale
ECS Cluster Architecture and Task Management
ECS clusters are logical groupings of EC2 instances or Fargate capacity where tasks execute. Unlike Kubernetes, ECS uses simpler concepts: Clusters contain EC2 instances (or Fargate), Tasks are running container definitions, and Services manage task replica counts and load balancing.
ECS Task Definition files (JSON or CloudFormation) specify container image, memory/CPU allocation, environment variables, logging configuration, and secrets management. Services maintain desired task count, automatically replacing failed tasks and distributing traffic across task replicas.
ECS Launch Types: EC2 vs. Fargate Performance Characteristics
ECS supports two launch types with distinct operational models:
- EC2 Launch Type: Requires EC2 instance management (patching, scaling, capacity planning). Provides full container customization and cost optimization through reserved instances. Optimal for stable, predictable workloads and organizations with strong AWS infrastructure expertise.
- Fargate Launch Type: Serverless container execution eliminating EC2 management. Automatic scaling based on resource requirements. Higher per-container cost but eliminates infrastructure operational burden. Optimal for variable workloads and operations-light teams.
ECS Load Balancing and Service Discovery
ECS Services integrate with Application Load Balancer (ALB), Network Load Balancer (NLB), and Classic Load Balancer (CLB) for traffic distribution. Service discovery through CloudMap enables service-to-service communication via DNS without hardcoded IP addresses.
For microservice architectures, CloudMap service registries combined with AWS Cloud Map-aware service discovery provide automatic registration and deregistration of container instances. This enables dynamic networking supporting auto-scaling scenarios.
3. EKS Architecture: Enterprise-Grade Kubernetes on AWS
Managed Kubernetes: AWS EKS Architecture and Control Plane Management
EKS provides managed Kubernetes control plane, eliminating cluster provisioning complexity. AWS manages API Server, etcd database, and controller components. Organizations deploy worker nodes (EC2 or Fargate) and manage applications running on Kubernetes.
EKS supports multiple worker node options: EC2 Auto Scaling Groups, Spot Fleet, and Fargate. Control plane multi-AZ replication ensures high availability. Organizations also leverage EKS-Optimized AMIs reducing operational overhead.
EKS Networking: VPC CNI and Advanced Network Policies
EKS uses AWS VPC CNI (Container Network Interface) plugin enabling pods to obtain VPC IP addresses directly. This approach differs from overlay networks, providing superior performance and simplified troubleshooting.
VPC CNI allocation uses AWS Elastic Network Interfaces (ENIs) and secondary IP addresses. Maximum pod density per node depends on ENI and IP limitations. Organizations optimize pod density through careful planning of IP space and ENI allocation.
EKS Multi-Cluster Strategies for High Availability
Production EKS deployments typically span multiple clusters across regions. AWS provides EKS Anywhere for on-premises deployments, enabling true hybrid strategies. Multi-cluster deployments require coordination of service discovery, data replication, and traffic routing.
Tools like AWS App Mesh simplify multi-cluster communication, providing service mesh capabilities for traffic management, security policies, and observability across clusters without application code changes.
4. Fargate: Serverless Container Execution and Operational Simplification
Fargate Architecture: Abstracting Infrastructure Complexity
Fargate abstracts infrastructure entirely, enabling developers to specify only CPU/memory requirements without managing underlying EC2 instances. AWS handles patching, scaling, and infrastructure provisioning transparently.
Fargate works with both ECS and EKS. With ECS, tasks launch on Fargate capacity managed by AWS. With EKS, pods scheduled on Fargate node groups execute on AWS-managed infrastructure. This dual support enables gradual ECS-to-EKS migration while leveraging serverless compute.
Fargate Cost Model and Optimization Strategies
Fargate charges per vCPU-hour and GB-hour of memory allocated. No charges for infrastructure management, patching, or scaling. Cost per container typically 30-50% higher than EC2 with reserved instances, but eliminates infrastructure operational overhead.
Optimization includes: right-sizing CPU/memory to actual requirements, implementing auto-scaling based on utilization metrics, using spot pricing for non-critical workloads (50-70% discount), and scheduling batch jobs during off-peak hours with savings plans.
Fargate Limitations and Workarounds
Fargate limitations include: maximum 4GB memory per task on AWS Graviton2 (10GB on x86), no privileged containers, limited host device access, no container socket mounts. These constraints suit most applications but require careful architectural planning for demanding workloads.
5. Migration Strategies: From Traditional Infrastructure to Container Orchestration
Assessing Current Infrastructure and Selection Criteria
AWS container orchestration selection requires evaluating: application architecture (monolithic vs. microservices), infrastructure control requirements, operational capabilities, budget constraints, and multi-cloud strategy. Organizations with cloud-only requirements and minimal operational constraints choose Fargate. Multi-cloud organizations select EKS. AWS-standardized organizations with full control requirements use ECS on EC2.
Migration Patterns: Lift-and-Shift vs. Refactoring
Lift-and-shift containerizes existing monolithic applications with minimal code changes. Typical timeline: 2-4 weeks per application. Benefits: rapid migration, reduced risk. Challenges: large image sizes, limited scalability.
Refactoring decomposes monoliths into containerized microservices. Typical timeline: 3-12 months. Benefits: independent scaling, deployment agility, team autonomy. Challenges: distributed systems complexity, operational overhead.
Phased Implementation Approach
Recommended implementation:
(1) Pilot phase with non-critical application validating technical approach and team capabilities (4-8 weeks).
(2) Foundation phase establishing infrastructure, monitoring, security, and CI/CD pipelines (6-8 weeks).
(3) Production rollout migrating critical workloads with rollback capability (3-6 months).
(4) Optimization phase tuning costs, performance, and operational processes (ongoing).
6. Cost Optimization Across AWS Container Orchestration Services
ECS on EC2 Cost Optimization: Reserved Instances and Spot Integration
ECS on EC2 baseline cost is EC2 instance pricing. Optimization includes: reserved instances (30-50% discount on stable workloads), spot instances (70-90% discount on interruptible workloads), and capacity providers automatically mixing on-demand, reserved, and spot for cost efficiency.
Capacity providers enable ECS to place tasks optimally across instance types and purchase options. Organizations achieve 40-60% cost reduction through proper capacity provider configuration combined with right-sized instance selection.
EKS Cost Management: Node Group Optimization and Karpenter
EKS cost optimization combines EC2 cost strategies with Kubernetes-native approaches. Karpenter, an open-source autoscaling solution, consolidates pods efficiently and removes underutilized nodes. Organizations report 50-70% cost reduction post-Karpenter implementation.
Additional strategies include: pod resource requests/limits matching actual consumption, horizontal pod autoscaling based on metrics, namespace resource quotas preventing runaway consumption, and scheduling pod disruption budgets during cost-optimized instance updates.
Fargate Cost Optimization: Right-Sizing and Spot Usage
Fargate optimization focuses on: accurate CPU/memory specification (oversized allocations inflate costs by 50-300%), utilizing Fargate Spot (70% discount for fault-tolerant workloads), implementing task auto-scaling based on metrics, and scheduling batch jobs during off-peak periods with lower rates.
Organizations track Fargate costs through CloudWatch custom metrics and AWS Cost Explorer. Setting budget alerts prevents cost surprises and enables reactive optimization.
7. Container Security: Image Security, Runtime Hardening, and Access Control
ECR Image Security: Scanning and Policy Enforcement
AWS Elastic Container Registry (ECR) provides integrated image scanning detecting vulnerabilities during push. ECR scan on push automatically scans images using open-source Clair technology. Organizations can enforce image pull policies preventing deployment of unscanned or vulnerable images.
Advanced security includes: image signing with Notary, encryption at rest using KMS keys, and private ECR repositories limiting access through IAM policies and VPC endpoints.
Runtime Security: IAM Roles, Secrets Management, and Network Policies
ECS Task IAM roles enable fine-grained permissions for containerized applications. Each task assumes a specific IAM role limiting AWS API access to required services. EKS uses IAM Roles for Service Accounts (IRSA) mapping Kubernetes service accounts to IAM roles.
Secrets management through AWS Secrets Manager or Parameter Store (with encryption) ensures sensitive data isolation. Network policies (ECS security groups, EKS network policies) restrict container-to-container communication preventing lateral movement.
Compliance and Container Isolation
ECS container isolation relies on cgroup resource limits and namespace isolation. EKS adds Kubernetes-level isolation through namespaces and pod security policies. Organizations requiring stronger isolation use Firecracker-based MicroVMs (AWS Bottlerocket OS) or AppArmor/SELinux policies.
8. Container Observability: Monitoring, Logging, and Distributed Tracing
CloudWatch Container Insights: Native AWS Observability
CloudWatch Container Insights provides ECS and EKS native monitoring showing cluster utilization, container performance, and application metrics. Integration with CloudWatch Logs enables centralized container logging.
Container Insights automatically instruments ECS task and EKS pod metrics without application code changes. Organizations gain visibility into container resource consumption, helping optimize sizing and auto-scaling policies.
ECS and EKS Logging Configuration
ECS supports multiple logging drivers: awslogs (CloudWatch Logs), splunk, awsfirelens (container agent wrapper). EKS logs flow through kubelet and container runtimes to CloudWatch Logs or external systems.
Best practices include: structured logging (JSON format), log retention policies managing storage costs, and centralized log aggregation for multi-cluster visibility. Organizations typically retain logs 7-30 days depending on compliance requirements.
Distributed Tracing with X-Ray and OpenTelemetry
AWS X-Ray integrates with ECS and EKS providing distributed tracing across service boundaries. OpenTelemetry integration (via AWS Distro) enables container-native tracing without vendor lock-in.
Tracing visibility reveals service dependencies, latency bottlenecks, and failure patterns. Organizations implementing comprehensive tracing detect performance issues automatically and reduce MTTR (Mean Time To Recovery).
9. Multi-Region Container Orchestration: Global Architecture Patterns
Multi-Region ECS Deployments with Auto Scaling
Multi-region ECS deployments require: infrastructure replication across regions, data synchronization strategies, and traffic routing policies. AWS Global Accelerator and Route 53 geolocation routing direct traffic to optimal regional endpoints.
Service discovery in multi-region ECS uses Route 53 weighted records or health-check-based routing. Organizations coordinate task placement across regions using separate ECS clusters with shared container images from multi-region ECR replication.
Multi-Region EKS: Federation and Cross-Cluster Communication
EKS multi-region deployments leverage EKS cluster federation or DNS-based load balancing. AWS Service Mesh (App Mesh) simplifies multi-region traffic management and security policies without application code changes.
Data consistency across regions requires eventual consistency models using event-driven replication or distributed databases (DynamoDB Global Tables, Aurora Global Database). Organizations trade immediate consistency for higher availability.
Disaster Recovery Across Regions
Multi-region orchestration provides disaster recovery enabling failover to secondary regions within minutes. RTO (Recovery Time Objective) typically 5-15 minutes with automated failover. RPO (Recovery Point Objective) depends on replication lag, typically 1-5 minutes.
10. Advanced Container Orchestration Patterns: Blue-Green Deployments, Canary Releases, and A/B Testing
Blue-Green Deployments with ECS and EKS
Blue-green deployments maintain two identical production environments. Traffic switches instantly from blue (old) to green (new) environment, enabling rapid rollback if issues occur. ECS supports blue-green through Task Set for Service.
EKS implements blue-green through traffic shifting via service mesh (App Mesh) or ingress controller. Organizations using blue-green achieve zero-downtime deployments with confidence in rapid rollback.
Canary Releases: Gradual Traffic Shifting
Canary releases shift small traffic percentages (5-10%) to new versions, monitoring for errors or performance degradation. If issues detected, rollback occurs automatically. If healthy, traffic gradually increases to 100%.
AWS Copilot and App Mesh enable canary releases with minimal application code changes. Organizations report 90% reduction in deployment-related incidents through canary release adoption.
A/B Testing and Feature Flags
Container orchestration enables sophisticated A/B testing splitting traffic between application versions. Feature flags decouple deployment from feature activation, enabling safe feature releases.
Organizations combine container orchestration with feature flag services (LaunchDarkly, AWS AppConfig) enabling per-user feature targeting and gradual rollout.
11. Production Challenges: Realistic Assessment and Mitigation Strategies
Container Image Management at Scale
Challenge: Managing hundreds of container images across multiple registries, versions, and regions requires sophisticated processes preventing stale, vulnerable images from deployment.
Solution: Implement image tagging standards (semantic versioning, git commit hashes), automated scanning on ECR push, retention policies deleting old images, and cross-region replication for disaster recovery.
Service Mesh Complexity vs. Security Benefits
Challenge: Service meshes (Istio, Linkerd, AWS App Mesh) provide observability and security but add operational complexity and CPU overhead.
Solution: Start with simpler approaches (ALB, network policies) and graduate to service mesh only if security/observability requirements justify complexity. AWS App Mesh offers tighter AWS integration reducing operational burden.
Cost Control and Budget Enforcement
Challenge: Dynamic container scaling can rapidly inflate costs if optimization is neglected. Organizations often experience 20-40% cost increases post-containerization.
Solution: Implement cost allocation tags, set CloudWatch alarms on cost thresholds, use budgets API for automated enforcement, and regularly review AWS Cost Explorer for optimization opportunities.
Operational Skills Gap and Knowledge Management
Challenge: Container orchestration requires specialized skills. Organizations struggle finding AWS container experts and managing knowledge across growing teams.
Solution: Invest in training programs, hire senior architects establishing patterns and standards, implement internal platforms abstracting complexity, and document architectural decisions with runbooks for common scenarios.
12. AWS Copilot: Simplifying Container Orchestration Complexity
Copilot Architecture and Workflow Automation
AWS Copilot provides CLI-driven containerized application deployment without deep AWS expertise. Copilot simplifies: infrastructure provisioning, service discovery, load balancing, observability, and CI/CD pipeline setup.
Copilot abstracts ECS/EKS selection, networking configuration, and security policies behind simple commands. Organizations deploying through Copilot achieve 50-75% faster deployment setup and reduced infrastructure complexity.
When to Use Copilot vs. Advanced Customization
Copilot excels for typical microservice architectures with standard patterns. Advanced requirements (custom networking, specialized compute, complex security policies) may require CloudFormation or IaC tools directly.
Many organizations start with Copilot for rapid deployment, then transition to advanced customization as requirements evolve. Copilot’s generated CloudFormation templates enable customization without rewriting from scratch.
Conclusion: AWS Container Orchestration as Strategic Cloud Foundation
AWS services ECS, EKS, Fargate, and App Runner—provide comprehensive solutions for deploying and managing containerized applications at scale. Success requires understanding each service’s strengths, matching them to organizational requirements, and implementing production-grade patterns for security, monitoring, and cost optimization.
Organizations mastering AWS container orchestration share common characteristics: clear service selection criteria based on requirements, investment in observability and security from inception, cost management discipline with right-sizing and optimization, and strong cloud-native engineering culture. The competitive advantage belongs to organizations moving rapidly from infrastructure to business logic.
AWS container orchestration continues evolving with managed service improvements, new compute options (AWS Graviton processors), and enhanced developer tools (AWS Copilot, CodeStar). Investment in container orchestration mastery delivers measurable business value through faster deployments, improved resource efficiency, and enhanced application availability.
