


If you evaluate aws glue and athena only as two standalone AWS services, you miss the real design pattern. Together, they form a serverless analytics stack for S3-based data lakes: Glue manages metadata, schema discovery, and ETL; Athena turns that metadata into interactive SQL over data stored in S3. The architectural value comes from how well you control schemas, file formats, partitions, permissions, and query spend.
Most blog posts stop at “crawl data in Glue, query it in Athena.” That is the beginner path, not the production path. In real environments, teams need to decide when crawlers are safe, when explicit schema control is better, how to avoid small-file explosions, when partition projection helps, whether Iceberg is worth the added metadata model, and how to keep analysts from turning ad hoc exploration into uncontrolled S3 scan costs.
This guide takes the architecture view. It explains where Glue and Athena fit in a modern data lake or lakehouse, how to design the S3 layout underneath them, where Lake Formation belongs, when Parquet and Iceberg change the economics, and when you should stop forcing the pattern and move to Redshift or EMR instead.
Why AWS Glue And Athena Still Matter In A Modern Amazon S3 Lakehouse:
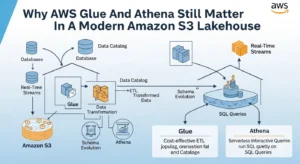
The main reason this pattern remains relevant is that it preserves the economics of S3 while avoiding the operational overhead of always-on query clusters. Athena is optimized for interactive analysis on data in S3, especially for ad hoc SQL, reporting exploration, and troubleshooting-style queries. Glue complements that by supplying a persistent metadata layer through the Glue Data Catalog and by handling data movement and transformation jobs that make Athena practical rather than merely possible.
Architecturally, Athena is the query plane and Glue is the metadata and transformation plane. That division matters because SQL engines are only as efficient as the table definitions, partitions, and file layouts they inherit. If Glue catalogs sloppy CSV dumps with unstable schemas and millions of tiny files, Athena will faithfully query them at a high cost. If Glue writes curated Parquet or Iceberg tables with disciplined partitions and up-to-date statistics, Athena becomes fast and economically predictable.
That is the key shift in mindset: aws glue and athena is not a “query my bucket” shortcut. It is a metadata-driven analytics architecture whose success depends on upstream data engineering discipline.
End-To-End Amazon S3 + AWS Glue + Amazon Athena Architecture:
A production design typically starts with S3 zones rather than a single bucket prefix. Raw landing data enters S3 from applications, logs, CDC feeds, or partner drops. Glue ETL jobs or streaming pipelines then transform that raw data into curated tables, ideally in Parquet, ORC, or Iceberg. The Glue Data Catalog stores metadata about databases, tables, partitions, and statistics. Athena reads that metadata, executes SQL against the S3 objects, and writes query results to a governed results bucket controlled through workgroup settings.
A clean reference model usually has four logical layers:
- Landing/raw: for immutable source-aligned ingestion
- Refined/curated: for cleaned and conformed datasets
- Consumer/serving: for BI-friendly tables
- Results/temporary: for Athena outputs and transient artifacts
This separation makes lifecycle policies, IAM policies, and retention rules much easier to operate.
For visualization and BI, Athena integrates naturally with tools such as QuickSight, JDBC/ODBC clients, and SQL consumers. But that consumption layer only works well when the storage and metadata layers are opinionated. Data teams that skip zone design often end up with one large S3 namespace that is cheap to create and expensive to govern.
Designing AWS Glue For Schema Governance, Not Just Crawling:
The Glue Data Catalog should be treated as the metadata contract for the lake, not a passive byproduct of crawler runs. AWS recommends consistent naming, logical grouping into databases, active schema management, encryption, monitoring, and integration with downstream analytics services. That means production teams should define naming standards, partition conventions, retention expectations, and ownership boundaries in the catalog itself.
Crawlers are powerful, but they are not neutral. They infer schema based on what they see, group data into tables or partitions based on heuristics, and can merge folders into a single logical table if schemas look similar enough. AWS even notes that using one include path for multiple different table roots can create Athena problems, including empty or misleading query results. In production, that means crawlers should be scoped carefully, often per dataset root, and not used as a substitute for data modeling.
The safer rule is simple: use crawlers for discovery, for onboarding, and for bounded areas where schema drift is acceptable. Use explicit ETL outputs and table definitions for curated datasets consumed by BI or external stakeholders. Review schema changes before applying them, especially where downstream SQL or dashboards depend on stable column types and names.
There is also an important distinction between the Glue Data Catalog and Glue Schema Registry. The Data Catalog governs table metadata for analytical data in S3. Schema Registry governs streaming message schemas and compatibility rules for systems like Kafka, Kinesis, Flink, and Lambda. If your architecture includes event streams feeding the lake, Schema Registry is how you stop schema evolution from breaking consumers before those records ever become Athena tables.
How Amazon Athena Really Works, And Why Cost Surprises Happen:
Athena’s pricing is straightforward on paper and often misunderstood in practice. For SQL queries, you pay by data scanned, currently listed as $5 per TB scanned, with additional S3 charges for reads, results storage, and related activity. AWS’s own pricing example shows the economics clearly: a 3 TB uncompressed text file queried for one column costs $15 to scan, while the same data compressed and converted to Parquet can bring that cost down to $1.25 because Athena scans fewer bytes and only the referenced column.
That means Athena cost is mostly a storage-layout problem disguised as a SQL problem. Analysts often assume “small query” equals “small bill,” but Athena charges by bytes processed, not rows returned. A SELECT count(*) against a badly organized dataset can be far more expensive than a complex filter against well-partitioned Parquet.
Workgroups are the main production control point. AWS recommends using them to separate workloads, control access, enforce settings like result location and encryption, track metrics, apply cost allocation tags, and attach usage controls. In practice, that means you should rarely let every user run against the default primary workgroup. Create separate workgroups for ad hoc analysts, scheduled reports, experimentation, and privileged engineering operations.
Athena also supports guardrails that many teams ignore: per-query data scan limits and workgroup-wide usage alerts. Per-query limits cancel expensive queries automatically, and workgroup-level thresholds can trigger SNS notifications or even disable a workgroup if budgets are breached. One subtle operational note from AWS: canceled or failed queries can still leave partial results or multipart uploads in S3, so the results bucket needs lifecycle hygiene as well.
For predictable concurrency-heavy workloads, provisioned capacity can make sense. AWS documents a model where you reserve DPUs for peak and off-peak windows rather than relying entirely on per-TB scanned billing. That is not the default choice for most teams, but it matters when Athena becomes part of a steady BI serving path instead of purely ad hoc analysis.
Optimizing AWS Glue And Athena With File Formats, Layout, And Compression:
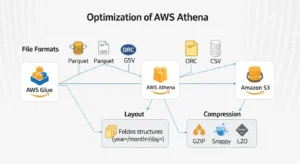
AWS is very explicit here: for Athena, use Parquet or ORC whenever possible. Both formats are columnar, support compression, enable predicate pushdown, and allow Athena to split reads across multiple readers for better parallelism. CSV remains useful as an ingestion format, not as a long-term analytical serving format.
Parquet is usually the default choice for mixed analytics workloads because it handles complex query patterns well and integrates naturally across AWS analytics tooling. ORC can produce smaller files and sometimes faster performance for Hive-oriented patterns. The right answer is empirical benchmarking, but the wrong answer is leaving large analytical datasets in plain text after ingestion.
From an implementation perspective, teams usually have two good conversion paths:
- use Athena CTAS for light-weight, SQL-centric format conversion
- use Glue ETL jobs for transformation-heavy, reusable data engineering pipelines
CTAS is attractive for one-step rewrites and rapid optimization. Glue is stronger when the pipeline needs validations, joins, custom code, or integration with broader ETL orchestration.
File size and path design matter too. AWS warns against too many small files and also against extra directory hierarchy inside a partition location because each extra S3 listing operation increases planning overhead. A common production target is fewer, larger files per partition and a flat structure under each partition prefix.
Partitioning, Partition Projection, And Small-File Handling:
Partitioning reduces cost because Athena can scan only the relevant partitions when the query contains filters on partition columns. But partitioning is not “the more the better.” AWS warns that too many partition keys can fragment datasets, produce too many tiny files, and increase catalog lookup and S3 listing overhead.
Use partition keys that match how the business actually filters data. Time is common, but not always enough. For log analytics, date plus service or environment may work. For BI, date plus region or business unit can work. Over-partitioning by low-value dimensions creates operational debt fast.
Hive-style partitioning gives you folder names like dt=2026-03-27/region=us/, which Athena can manage more easily using MSCK REPAIR TABLE. Non-Hive-style layouts need manual partition registration through ALTER TABLE ADD PARTITION. If your data layout is highly predictable and extremely partitioned, partition projection can remove the metadata lookup step by letting Athena infer partitions from table properties.
Partition projection is powerful, but it is not automatically better. AWS notes that if more than half the projected partitions are empty, performance can actually be worse than traditional partition metadata because Athena still projects paths that do not contain data. The right use case is dense, predictable partition spaces, not sparse guesswork.
Small files are the other half of the problem. AWS explicitly warns that many small files hurt overall query performance. If your pipeline writes endless micro-batches to S3, Athena planning overhead rises and the benefit of partitioning collapses. This is where compaction enters the architecture, either through Glue ETL rewrites, Athena CTAS rewrites, or Iceberg-native optimization.
Apache Iceberg As The Modern Lakehouse Layer:
If your lake is evolving from “external tables over files” to “managed analytical tables,” Iceberg is the most important upgrade in this stack. AWS Glue supports Iceberg natively in ETL jobs, and Athena supports creating, querying, and optimizing Iceberg tables through the Glue Data Catalog. That means you can get transactional consistency, hidden partitioning, schema evolution, and snapshot-based operations without abandoning S3.
Iceberg changes two things immediately. First, it reduces the operational pain of partition management because hidden partitioning and table metadata handle more of the complexity. Second, it gives you maintenance operations that are much closer to a warehouse experience, including OPTIMIZE for compaction and VACUUM for snapshot expiration and orphan-file cleanup.
Athena’s OPTIMIZE … REWRITE DATA USING BIN_PACK is especially relevant for small-file cleanup and delete-file overhead. AWS notes that this rewrite is transactional and charged by the amount of data scanned during compaction, so compaction itself should be targeted, often by partition predicate, rather than run blindly across the whole table.
Iceberg also unlocks better planning through statistics. Athena can use Iceberg statistics for cost-based optimization, and Parquet column indexes can enable more precise pruning during execution. This is where Glue’s metadata role becomes even more strategic: better stats mean better join ordering, filter pushdown, and lower scan costs.
Security, Governance, And Fine-Grained Access Control:
In production, IAM and Lake Formation are complementary, not interchangeable. IAM controls access to APIs and service operations, while Lake Formation controls permissions on data and metadata, including table-, column-, row-, and cell-level access for Athena SQL over S3-backed tables. That is the boundary most data platforms need when analysts and BI tools should not see everything in a bucket just because they can run SQL.
Lake Formation is particularly valuable when Glue Data Catalog tables represent shared enterprise assets. You can apply permissions through named resources or LF-tags, secure data filters, and even support cross-account sharing patterns. For Athena-based data lakes, this turns the Glue catalog from a passive metadata store into an enforceable governance layer. Many organizations work with GoCloud and its cloud security consulting services when implementing governed AWS analytics environments to ensure permissions and governance controls are properly aligned across data platforms.
Glue itself also supports fine-grained controls with Lake Formation in Spark jobs, especially in Glue 5.0 and later. But AWS notes operational consequences: FGAC jobs need at least four workers and can incur additional charges, which means you should reserve that model for datasets where row/column isolation is worth the runtime complexity.
Do not ignore metadata security. AWS supports KMS-based encryption for the Glue Data Catalog itself, covering databases, tables, partitions, statistics, and related metadata objects. This matters because metadata often exposes sensitive meaning even when the underlying data is separately protected.
Cost And Performance Tuning Playbook:
The most effective cost controls are architectural:
- convert raw text to Parquet or ORC
- partition only on real filter dimensions
- compact small files
- gather table and column statistics
- isolate workloads with workgroups
- set query limits and alerts
These levers consistently matter more than one-off SQL micro-optimizations. AWS Athena Pricing Athena Data Optimization Athena Cost-Based Optimizer Athena Data Usage Controls
Statistics are underrated. Athena’s cost-based optimizer can use table and column statistics stored in the Glue Data Catalog to create better execution plans, especially for filters, joins, and aggregations. If you have Hive or Iceberg tables that matter to the business, generating and refreshing statistics should be a standard optimization task, not a once-a-year emergency fix.
Operationally, monitor these every week:
- top scanning queries by workgroup
- average data scanned per query
- failed and canceled query counts
- tables with stale or missing statistics
- partitions with runaway file counts
- S3 results buckets accumulating partial outputs
That is how you turn Athena from a handy SQL endpoint into a governable platform.
When Glue + Athena Is Enough, And When Amazon Redshift Or Amazon EMR Is Better:
Glue + Athena is enough when the priority is serverless analytics on S3, interactive SQL, governed metadata, and reasonably simple transformation pipelines. It shines for log analytics, ad hoc data exploration, data lake BI, and team workflows that benefit from low operational overhead.
Redshift becomes the better answer when the workload is fundamentally warehouse-shaped: highly structured datasets, many large joins, long-lived historical reporting, and a need for consistently optimized query performance on curated relational models. AWS says that when you need complex queries across large structured tables, Redshift is the best choice.
EMR becomes the better fit when you need custom code, custom frameworks, full Spark/Hadoop control, specialized libraries, or very large-scale data processing that outgrows serverless ETL abstractions. AWS positions EMR for big data processing, large transformations, streaming, machine learning, and custom application logic with more control over compute shape and runtime environment.
The mature answer is often hybrid. Use Glue + Athena for lake metadata and exploratory SQL, Redshift for high-value warehouse consumption, and EMR where custom Spark engineering is unavoidable. AWS’s own analytics decision framework points to this service-by-use-case approach rather than a single-tool mentality.
Real Implementation Scenarios:
For log analytics, this stack is excellent. Raw logs land in S3, Glue registers or transforms them, Athena queries recent partitions, and QuickSight or operational dashboards consume curated views. Partition projection is especially useful here when date- or service-based partitions are dense and predictable.
For BI and dashboard serving, the winning pattern is to keep source-aligned raw data separate and expose only curated Parquet or Iceberg tables through governed workgroups and Lake Formation policies. This reduces cost variance and gives BI teams a stable semantic surface.
For ad hoc exploration, Athena is one of the fastest ways for data engineers and analytics engineers to ask questions of S3 without standing up infrastructure. The trick is to isolate that freedom in its own workgroup, with tight data-scan limits and a separate results bucket, so experimentation does not bleed into production cost.
Frequently Asked Questions:
Is AWS Glue And Athena A Lakehouse By Itself?
Not automatically. It becomes a lakehouse pattern when you add disciplined table design, governed metadata, open table formats such as Iceberg, and operational controls around access, compaction, and optimization.
What Is The Safest Way To Start With Glue And Athena?
Start with raw data in S3, define clean dataset boundaries, use Glue to catalog or transform into Parquet, and put Athena queries behind workgroups. That gives you a low-friction path without locking you into a warehouse too early.
Should I Use Glue Crawlers On Curated Tables?
Usually only with caution. For high-trust curated tables, explicit schema control is safer than open-ended inference, especially where dashboards or downstream ETL depend on schema stability.
What Is The Easiest Way To Reduce Athena Spend Fast?
Convert text data to Parquet or ORC, compress it, and ensure queries filter on partition columns. Those three changes usually reduce scan volume far more than SQL rewrites alone.
Is Partition Projection Always Better Than Glue Partitions?
No. It is better for highly partitioned, predictable datasets, but not for sparse layouts with many empty partitions. AWS explicitly calls out that empty projected partitions can hurt performance.
Conclusion:
The best way to think about aws glue and athena is not as a simple pairing of “ETL plus SQL,” but as a metadata-first serverless lakehouse architecture on S3. When you combine disciplined Glue catalog management, columnar storage, smart partition design, Iceberg where it adds real value, and Athena workgroup governance, you get a platform that is flexible for exploration, efficient for BI, and much safer in production. When those controls are absent, the same stack turns into a noisy, expensive query surface over badly organized files. That is why the winning architecture is not the one that deploys Glue and Athena the fastest; it is the one that designs for schema stability, file economics, access control, and operational cost from day one.


