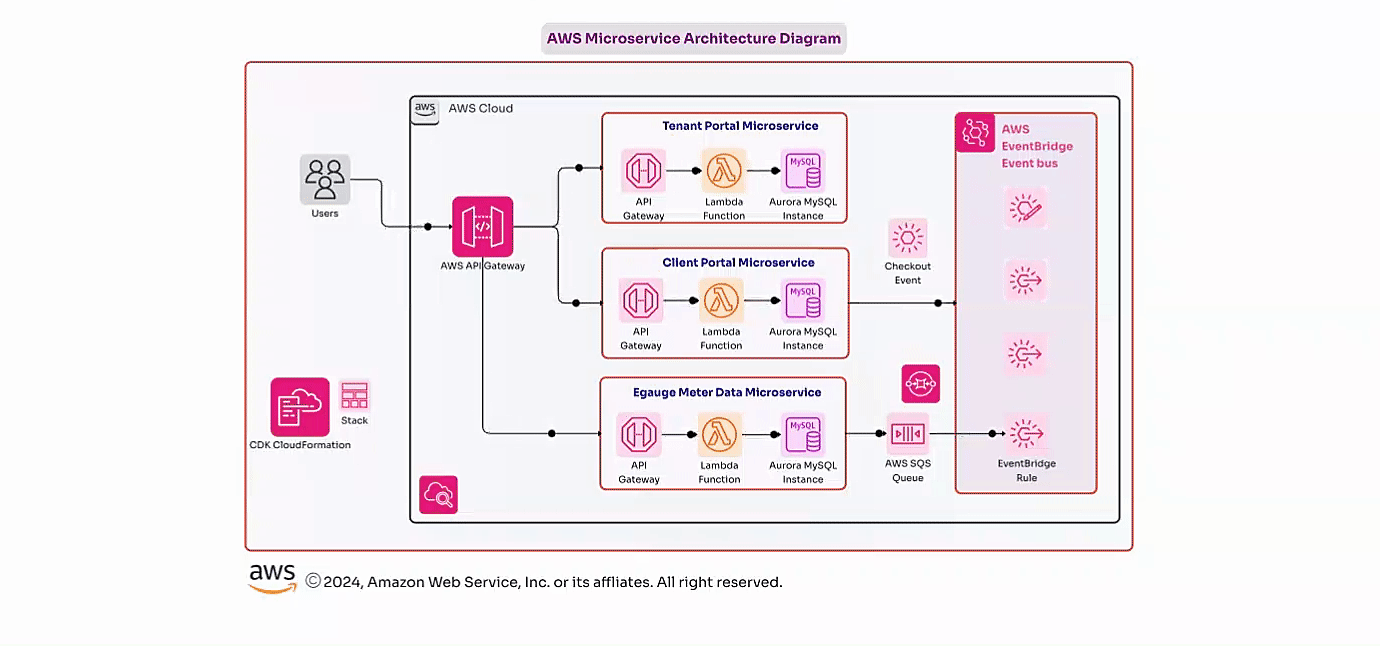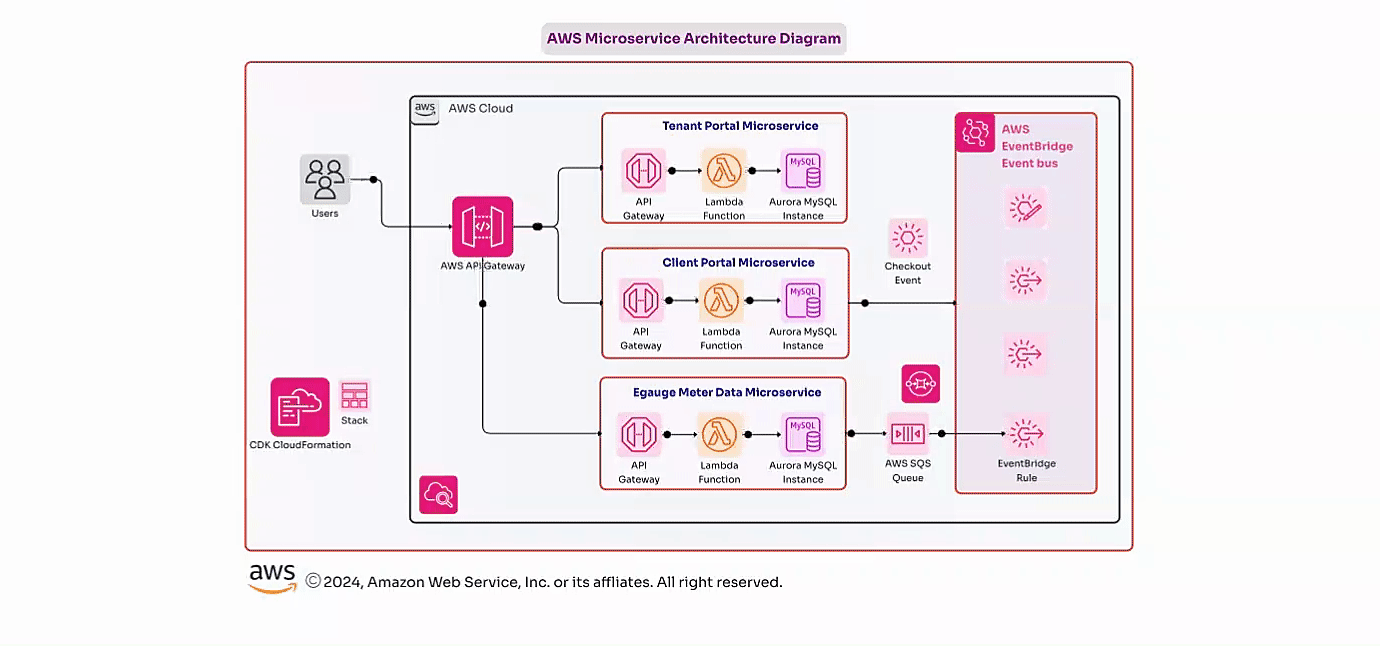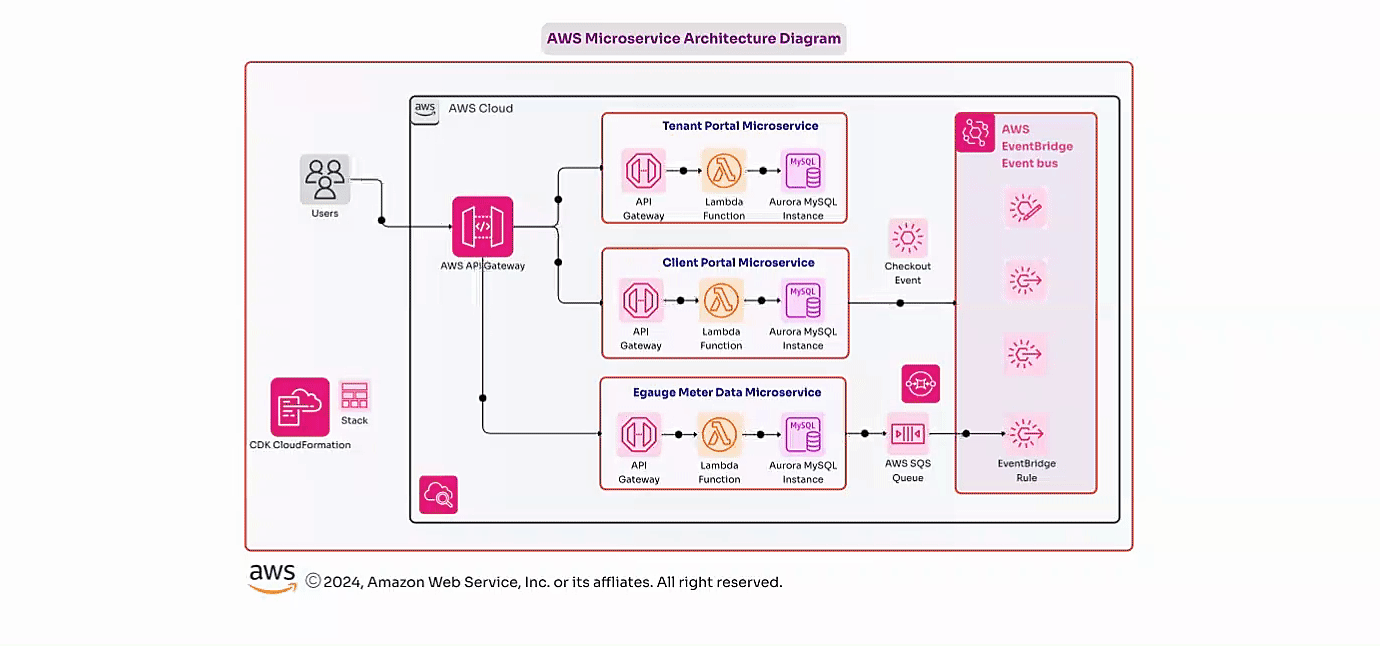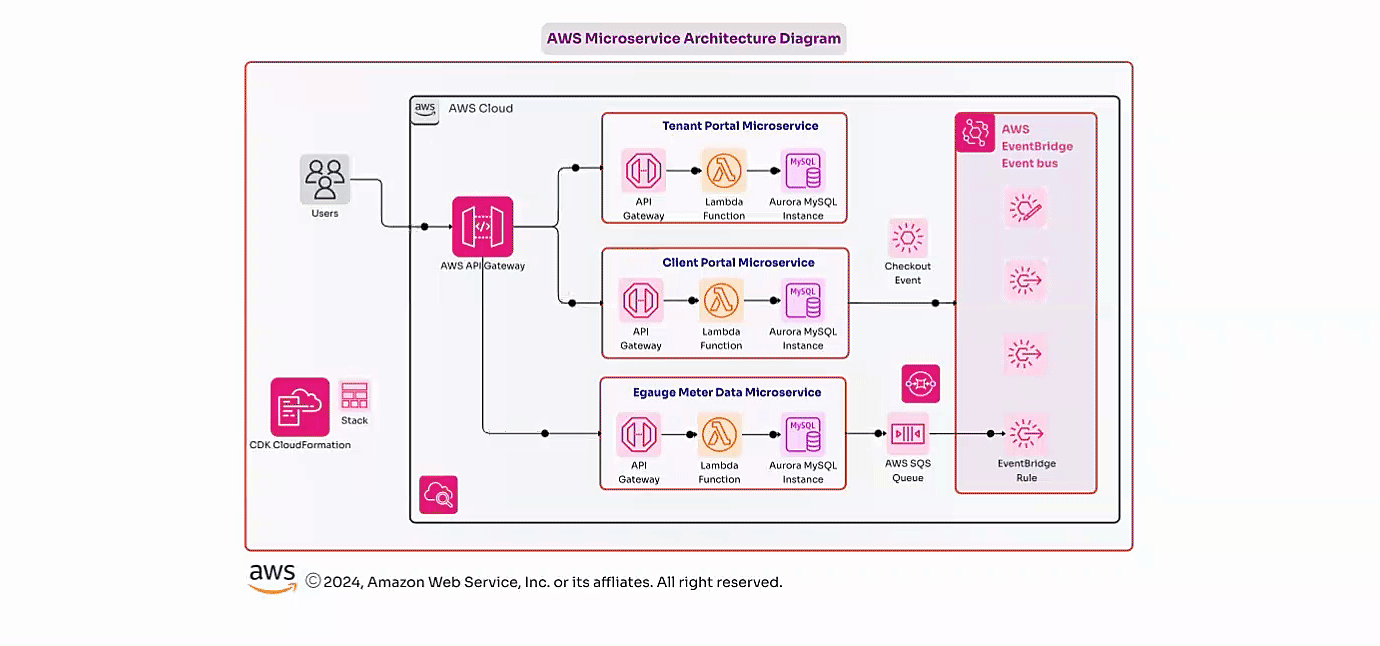
A large financial investment firm with critical applications requiring high availability and disaster recovery capabilities faced challenges with their existing on-premises disaster recovery (DR) solution. The outdated DR setup was costly to maintain and slow to restore services, creating a risk of significant financial losses due to unplanned downtimes.
Problem
1.Outdated DR Solution:
The current on-premises DR setup is expensive to maintain and slow to restore services.
2.High Potential for Financial Losses:
Risk of substantial financial losses due to unplanned downtimes.
3.Lack of Automation:
Manual processes for failover and recovery lead to increased recovery times and inefficiencies.
Solution Approach
We implemented a cost-effective and automated disaster recovery solution using AWS services:
Route 53:
For DNS failover to automatically route traffic to the DR site in case of a disaster.
S3:
For storing backups and data replication.
EC2 & Auto Scaling:
For running instances in the DR region and scaling them as needed.
RDS Multi-AZ:
To provide automatic failover for databases.
CloudFormation:
To automate the provisioning of infrastructure in the DR region.
AWS Backup:
To automate and centralize backup management across AWS services.
CloudEndure Disaster Recovery:
For continuous block-level replication and near-zero RPO (Recovery Point Objective).
Implementation
The disaster recovery plan was implemented according to the client’s current infrastructure and business continuity requirements:
1.Data Replication:
Implemented real-time data replication from the primary region to the DR region using CloudEndure Disaster Recovery.
2.Multi-AZ Setup:
Deployed RDS instances in a Multi-AZ configuration to ensure high availability of databases.
3.Backup Strategy:
Utilized AWS Backup to automate backups across services, ensuring data integrity and availability.
4.Infrastructure as Code (IaC):
Created CloudFormation templates to replicate the primary environment in the DR region quickly.
5.DNS Failover:
Configured Route 53 for DNS failover to route traffic to the DR site automatically in case of a failure in the primary region.
6.Testing & Validation:
Performed regular failover and failback testing to ensure the DR solution works as expected and meets the required RTO (Recovery Time Objective) and RPO.
7.Testing & Validation:
Performed regular failover and failback testing to ensure the DR solution works as expected and meets the required RTO (Recovery Time Objective) and RPO.
8.Automation:
Automated failover processes to reduce recovery time and human intervention during a disaster.
Benefits
1.Reduced Downtime:
Achieved near-zero RPO and minimal RTO, significantly reducing the risk of downtime.
2.Cost Savings:
Reduced the cost of maintaining a secondary on-premises DR site by utilizing AWS’s pay-as-you-go model.
3.Enhanced Security:
Ensured data security and compliance with industry regulations through automated encryption and access controls.
4.Scalability:
The DR environment can scale up automatically during a disaster, providing the necessary resources on demand.