An insurance company faces challenges in managing and processing large volumes of policy and claim data. This data arrives in various formats—nested, flat, file-based, tabular, and relational—making it difficult to consolidate, cleanse, and analyze efficiently. The company lacks a unified platform to manage the data lifecycle, from ingestion to transformation, storage, and analysis. They need a solution to automate data processing workflows, ensure data quality, and provide actionable insights through advanced analytics and reporting tools. Current manual processes are time-consuming, error-prone, and do not scale well with increasing data volumes.
Solution Overview
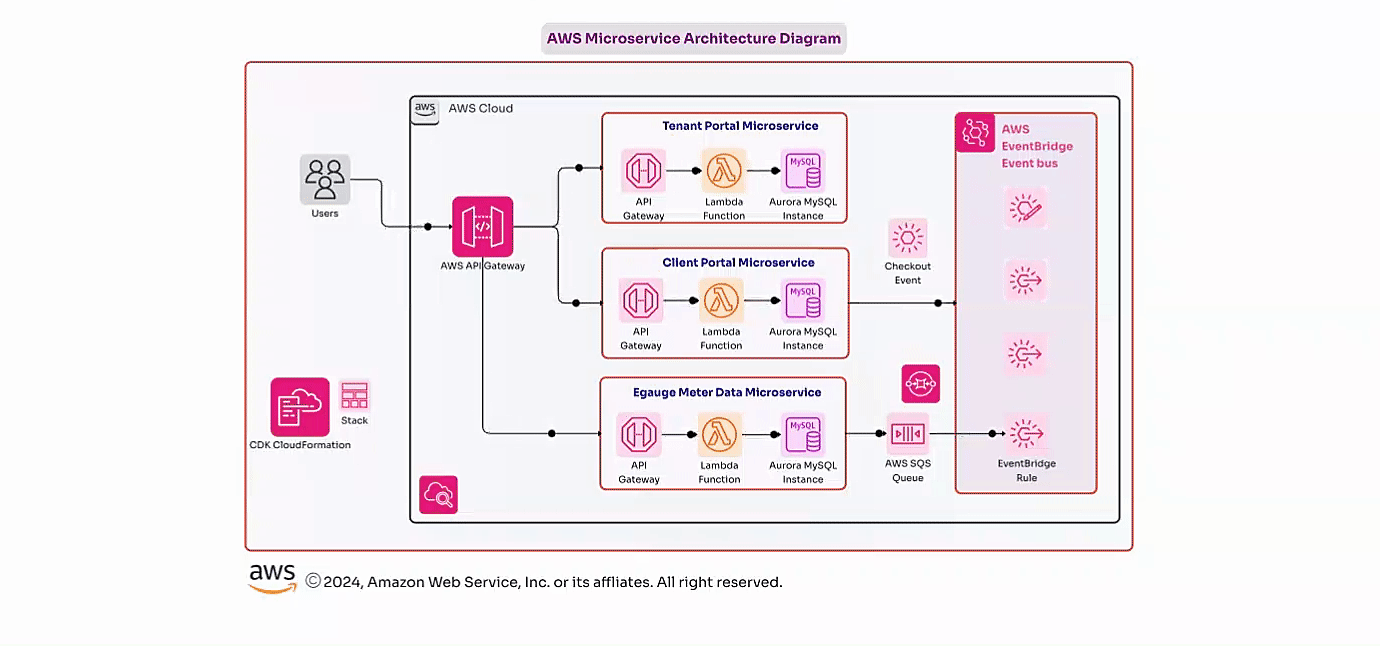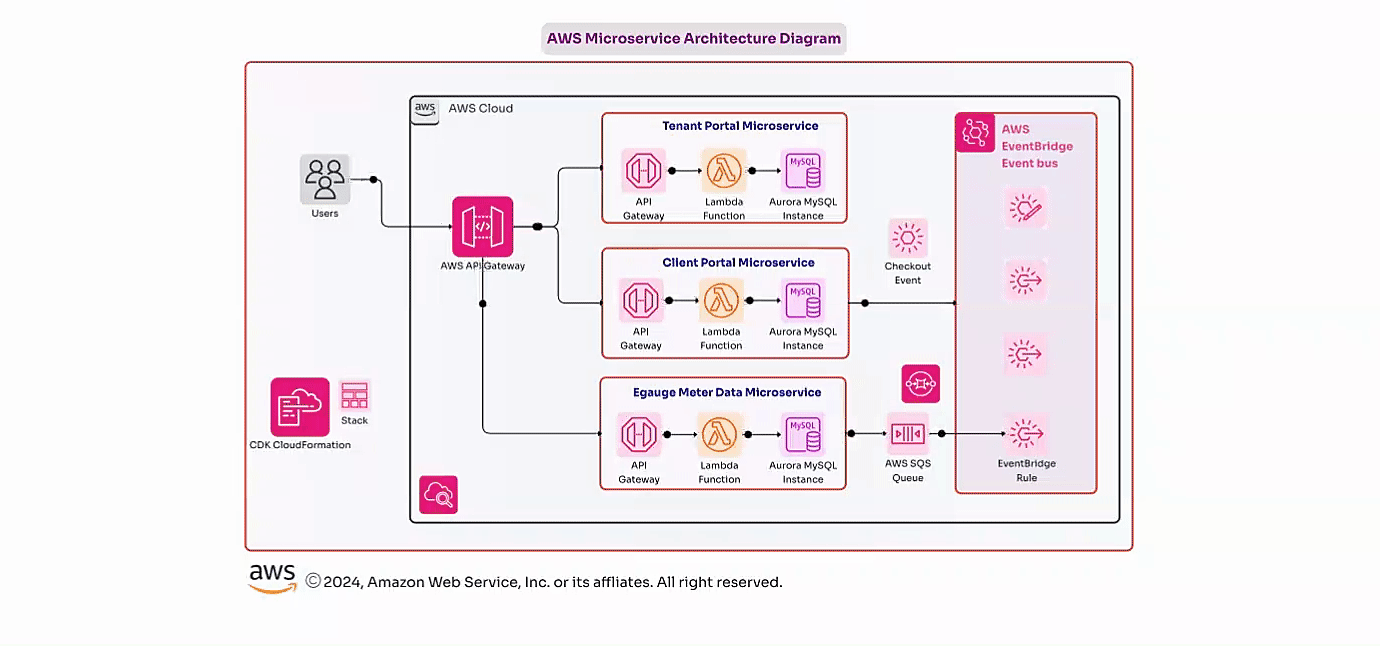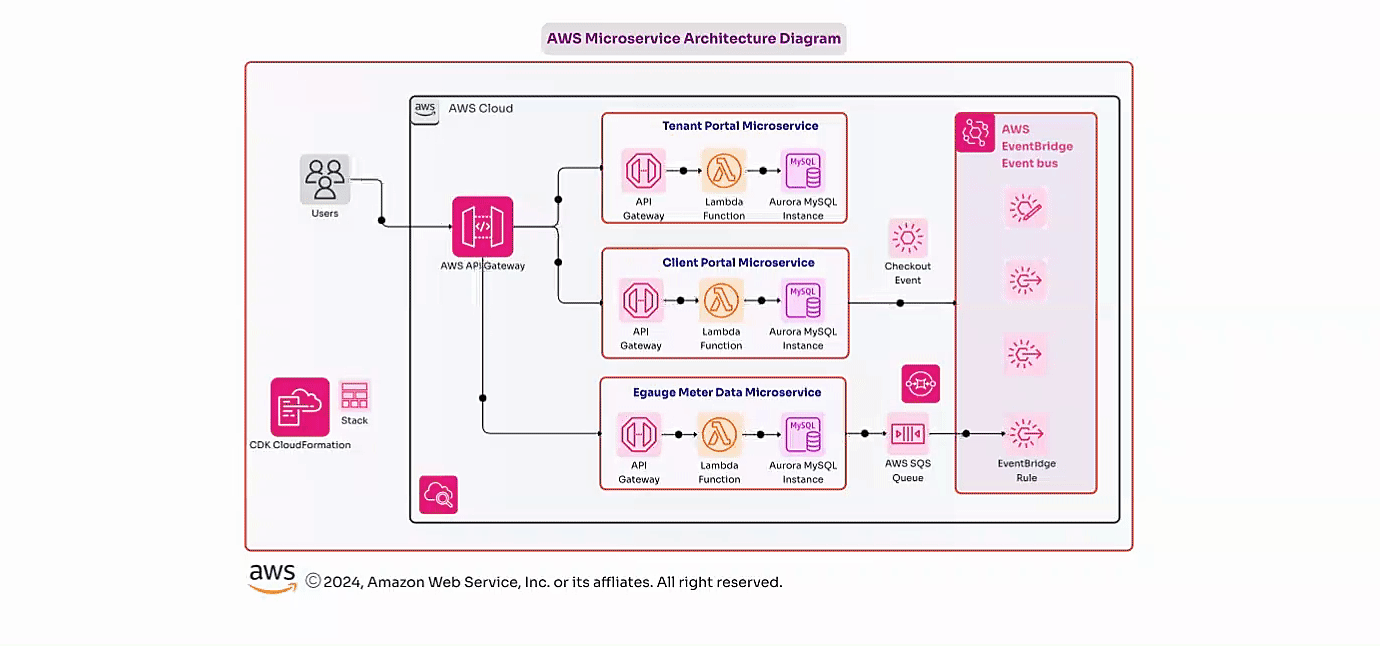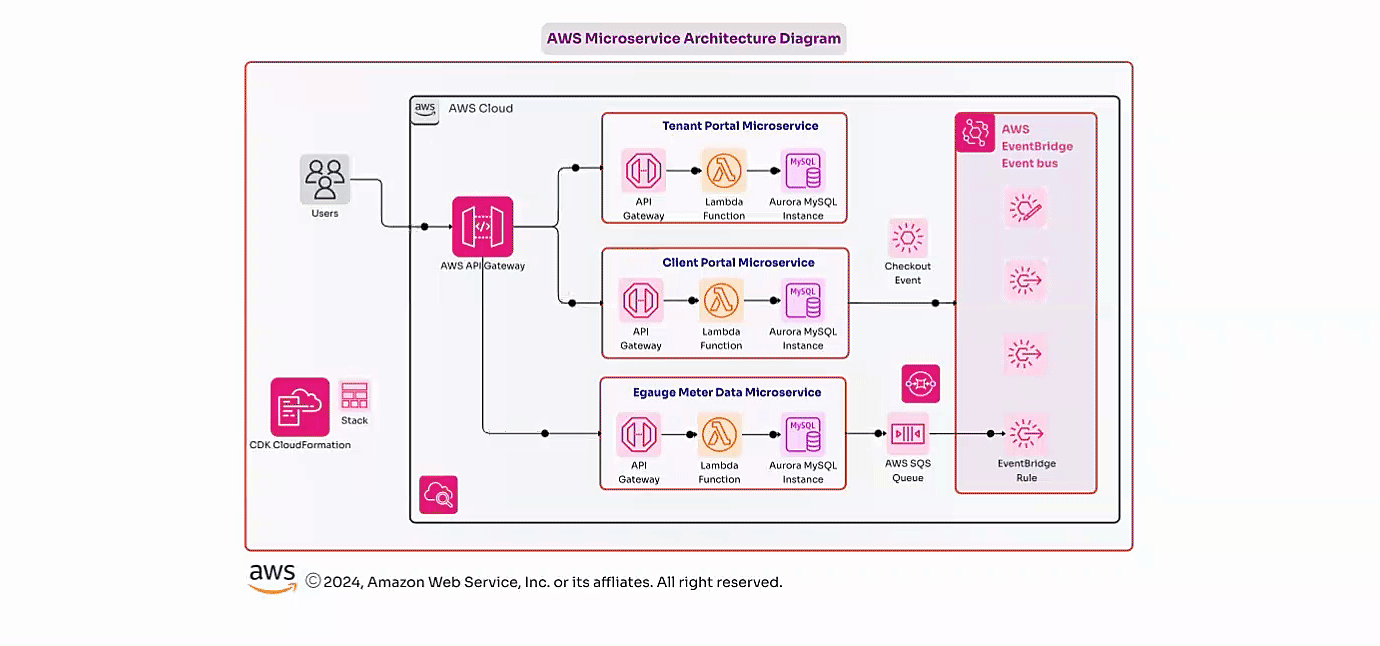
To address these challenges, the proposed solution is a scalable and automated data lake architecture on AWS, tailored specifically for the insurance industry. This architecture will ingest, cleanse, transform, store, and analyze policy and claim data, regardless of its format. The solution leverages AWS services to build a unified platform that automates data processing workflows, ensures data quality, and enables advanced analytics and reporting. By implementing this architecture, the insurance company will efficiently manage large datasets, reduce operational overhead, and gain valuable insights from their data.
Solution Capabilities
1.Data Ingestion:
Efficiently ingest large volumes of policy and claim data in various formats.
Securely store raw data in a centralized data lake on Amazon S3.
2.Data Transformation and Cleansing:
Automate data cleansing, transformation, and enrichment processes using AWS Glue.
Ensure data quality and consistency before storage for analysis.
3.Pipeline Metadata Management:
Track and manage the state of data processing workflows using Amazon DynamoDB for metadata storage.
4.Workflow Orchestration:
Use AWS Step Functions to orchestrate the entire data processing workflow, ensuring tasks are executed in the correct sequence.
5.Scalable Data Storage:
Store cleansed and transformed data in a query-efficient format (e.g., Parquet files) on Amazon S3, ensuring scalability and cost-efficiency.
6.Data Cataloging and Discoverability:
Utilize AWS Glue Data Catalog to organize and catalog the processed data, making it easily discoverable for analysis.
7.Advanced Analytics and Reporting:
Enable ad-hoc querying of the data using Amazon Athena.
Provide data visualization and reporting capabilities through Amazon QuickSight, empowering stakeholders to make informed decisions.
8.Automation and Continuous Integration:
Implement continuous integration and deployment of data processing workflows using AWS CodePipeline, ensuring the architecture remains efficient and up-to-date.